I’m drafting a new social epistemology section for the SEP entry on formal epistemology. It’ll focus on a series of three papers that study epistemic networks using computer simulations. This post is the first in a series of three explainers, one on each paper.
In each post I’ll summarize the main ideas and replicate some key results in Python. You can grab the final code from GitHub if you want to play along and tinker.
The Idea
More information generally means a better chance at discovering the truth, at least from an individual perspective. But not as a community, Zollman finds, at least not always. Sharing all our information with one another can make us less likely to reach the correct answer to a question we’re all investigating.
Imagine there are two treatments available for some medical condition. One treatment is old, and its efficacy is well known: it has a .5 chance of success. The other treatment is new and might be slightly better or slightly worse: a .501 chance of success, or else .499.
Some doctors are wary of the new treatment, others are more optimistic. So some try it on their patients while others stick to the old ways.
As it happens the optimists are right: the new treatment is superior (chance .501 of success). So as they gather data about the new treatment and share it with the medical community, its superiority will eventually emerge as a consensus, right? At least, if all our doctors see all the evidence and weigh it fairly?
Not necessarily. It’s possible that those trying the new treatment will hit a string of bad luck. Initial studies may get a run of less-than-stellar results, which don’t accurately reflect the new treatment’s superiority. After all, it’s only slightly better than the traditional treatment. So it might not show its mettle right away. And if it doesn’t, the optimists may abandon it before it has a chance to prove itself.
One way to mitigate this danger, it turns out, is to restrict the flow of information in the medical community. Imagine one doctor gets a run of bad luck—a string of patients who don’t do so well with the new treatment, creating the misleading impression that the new treatment is inferior. If they share this result with everyone, it’s more likely the whole community will abandon the new treatment. Whereas if they only share it with a few colleagues, others will keep trying the new treatment a while longer, hopefully giving them time to discover its superiority.
The Model
We can test this story by simulation. We’ll create a network of doctors, each with their own initial credence that the new treatment is superior. Those with credence > .5 will try the new treatment, others will stick to the old. Doctors directly connected in the network will share results with their neighbours, and everyone will update on whatever results they see using Bayes’ theorem.
We’ll consider networks of different sizes, from 3 to 10 agents. And we’ll try three different network “shapes”: complete, wheel, and cycle.
These shapes vary in their connectedness. The complete network is fully connected, while the cycle is the least connected. Each doctor only confers with their two neighbours in the cycle. The wheel is in between.
Our conjecture is that the cycle will prove most reliable. A doctor who gets a run of bad luck—a string of misleading results—will do the least damage there. Sharing their results might discourage their two neighbours from learning the truth. But the others in the network may keep investigating, and ultimately learn the truth about the new treatment’s superiority. The wheel should be more vulnerable to accidental misinformation, however, and the complete network most vulnerable.
Nitty Gritty
Initially, each doctor is assigned a random credence that the new treatment is superior, uniformly from the [0, 1] interval.
Those with credence > .5 will then try the new treatment on 1,000 patients. The number of successes will be randomly determined, according to the binomial distribution with probability of success .501.
Each doctor then shares their results with their neighbours, and updates by Bayes’ theorem on all data available to them (their own + neighbors’). Then we do another round of experimenting, sharing, and updating, followed by another, and so on until the community reaches a consensus.
Consensus can be achieved in either of two ways. Either everyone learns the truth that the new treatment is superior: credence > .99 let’s say. Alternatively, everyone might reach credence ≤ .5 in the new treatment. Then no one experiments with it further, so it’s impossible for it to make a comeback. (The .99 cutoff is kind of arbitrary, but it’s very unlikely the truth could be “unlearned” after that point.)
Results
Here’s what happens when we run each simulation 10,000 times. Both the shape of the network and the number of agents affect how often the community finds the truth.
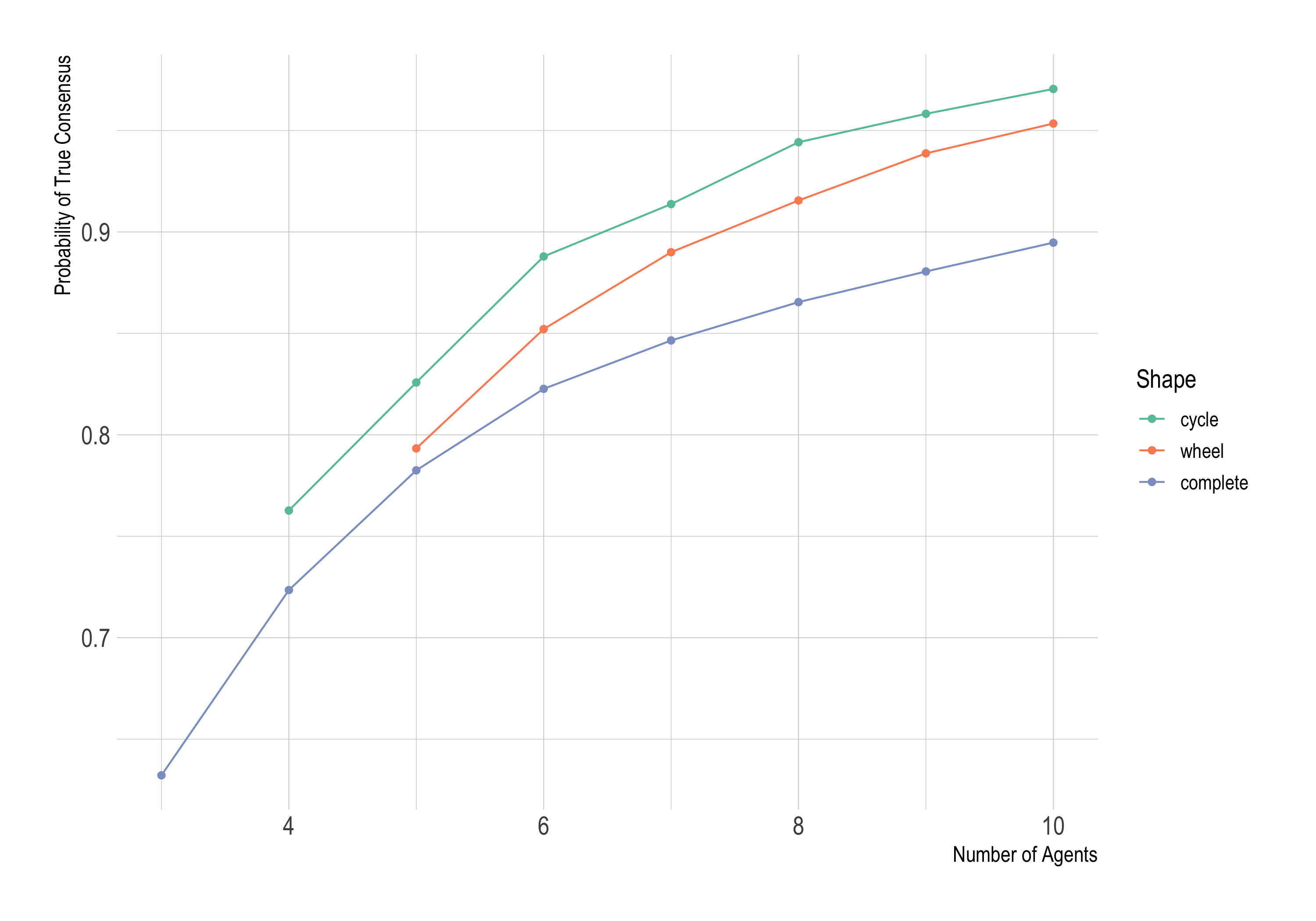
The less connected the network, the more likely they’ll find the truth. And a bigger community is more likely to find the truth too. Why?
Bigger, less connected networks are better insulated against misleading results. Some doctors are bound to get data that don’t reflect the true character of the new treatment once in a while. And when that happens, their misleading results risk polluting the community with misinformation, discouraging others from experimenting with the new treatment. But the more people in the network, the more likely the misleading results will be swamped by accurate, representative results from others. And the fewer people see the misleading results, the fewer people will be misled.
Here’s an animated pair of simulations to illustrate the second effect. Here I set the six scientists’ starting credences to the same, even spread in both networks: .3, .4, .5, .6, .7, and .8. I also gave them the same sequence of random data. Only the connections in the networks are different, and in this case it makes all the difference. Only the cycle learns the truth. The complete network goes dark very early, abandoning the novel treatment entirely after just 26 iterations.
What saves the cycle network is the agent who starts with .8 credence (bottom left). She starts out optimistic enough to keep going after the group encounters an initial string of dismaying results. In the complete network, however, she receives so much negative evidence early on that she gives up almost right away. Her optimism is overwhelmed by the negative findings of her many neighbours. Whereas the cycle exposes her to less of this discouraging evidence, giving her time to keep experimenting with the novel treatment, ultimately winning over her neighbours.
As Rosenstock, Bruner, and O’Connor put it: sometimes less is more, when it comes to sharing the results of scientific inquiry. But how important is this effect? How often is it present, and is it big enough to worry about in actual practice? Next time we’ll follow Rosenstock, Bruner, and O’Connor further and explore these questions.